
Github
Instruction-tune Llama 2 a guide to training Llama 2 to generate instructions from inputs transforming the model from instruction-following to instruction-giving. You can try out Text Generation Inference on your own infrastructure or you can use Hugging Faces Inference Endpoints To deploy a Llama 2 model go to the model page and click on the Deploy -. Training LLMs can be technically and computationally challenging In this section we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple. Select the Llama 2 model appropriate for your application from the model catalog and deploy the model using the PayGo option You can also fine-tune your model using MaaS from Azure AI Studio and. LLaMA-2-7B-32K is an open-source long context language model developed by Together fine-tuned from Metas original Llama-2 7B model This model represents our efforts to contribute to..
Result Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. Result Run and fine-tune Llama 2 in the cloud Chat with Llama 2 70B Customize Llamas personality by clicking the settings button. Result Llama 1 released 7 13 33 and 65 billion parameters while Llama 2 has7 13 and 70 billion parameters Llama 2 was trained on 40 more data. We are releasing Code Llama 70B the largest and best-performing model in the Code Llama family. Result Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters..
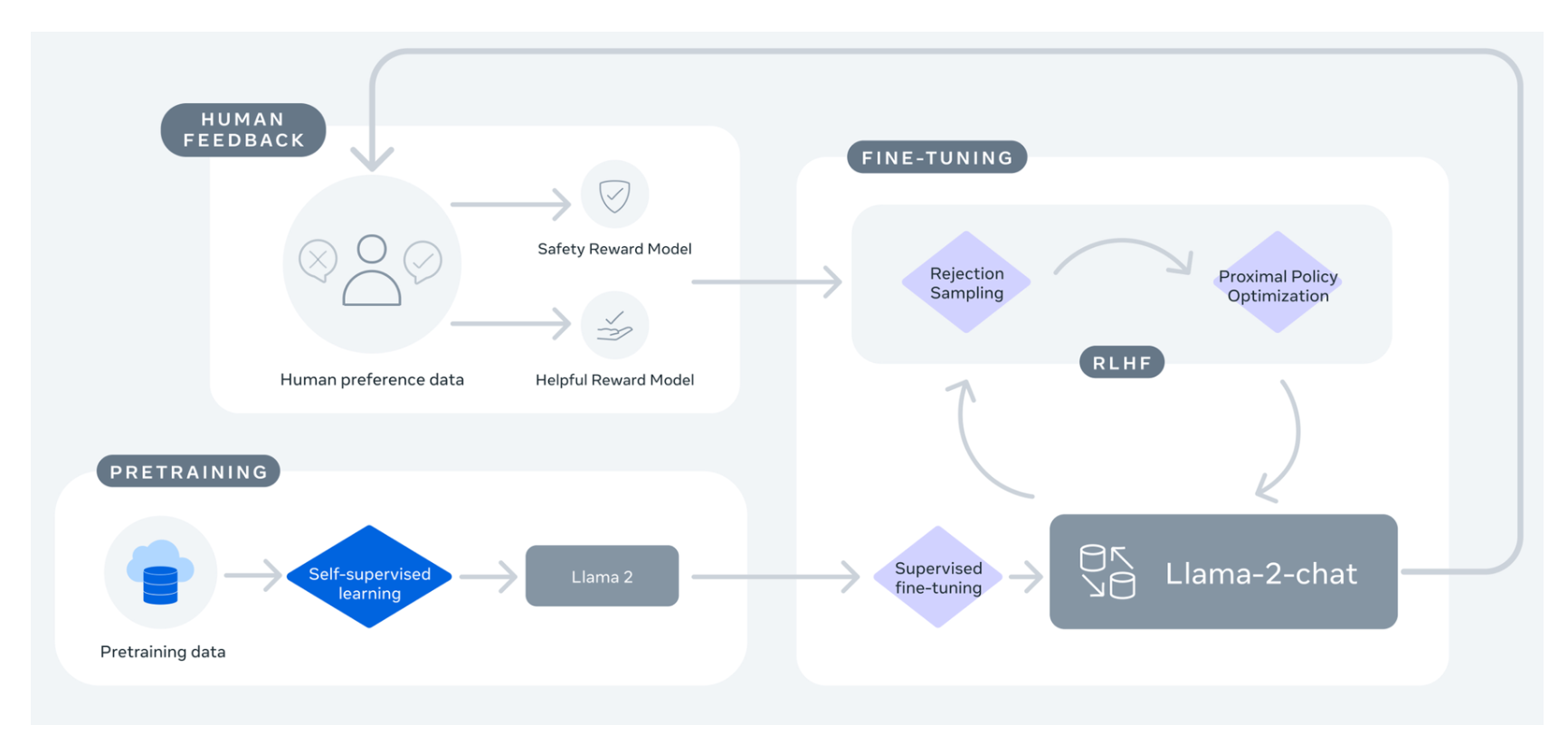
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale. Alright the video above goes over the architecture of Llama 2 a comparison of Llama-2 and Llama-1 and finally a. Result The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate fine-tune the models. Open Foundation and Fine-Tuned Chat Models Last updated 14 Jan 2024 Please note This post is mainly intended for. Result Our pursuit of powerful summaries leads to the meta-llamaLlama-27b-chat-hf model a Llama2 version with 7 billion parameters..
. . . WEB Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7 billion to 70 billion parameters Below you can find and download LLama 2. WEB Here is my current code that I am using to run it Model_name_or_path TheBlokeLlama-2-70B-Chat-GGML model_basename llama-2-70b..

Medium



Comments